
Overview
Source #1
The NetApp filer also know as NetApp Fabric-Attached Storage (FAS) is a type of disk storage device which owns and controls a filesystem and present files and directories over the network, it uses an operating systems called Data ONTAP (based on FreeBSD).
NetApp Filers can offer the following:
- Supports SAN, NAS, FC, SATA, iSCSI, FCoE and Ethernet all on the same platform
- Supports either SATA, FC and SAS disk drives
- Supports block protocols such as iSCSI, Fibre Channel and AoE
- Supports file protocols such as NFS, CIFS , FTP, TFTP and HTTP
- High availability
- Easy Management
- Scalable
The NetApp Filer also know as NetApp Fabric-Attached Storage (FAS), is a data storage device, it can act as a SAN or as a NAS, it serves storage over a network using either file-based or block-based protocols:
- File-Based Protocol: NFS, CIFS, FTP, TFTP, HTTP
- Block-Based Protocol: Fibre Channel (FC), Fibre channel over Ethernet (FCoE), Internet SCSI (iSCSI)
The most common NetAPP configuration consists of a filer (also known as a controller or head node) and disk enclosures (also known as shelves), the disk enclosures are connected by Fibre Channel or parallel/serial ATA, the filer is then accessed by other Linux, Unix or Window servers via a network (Ethernet or FC).
All filers have a battery-backed NVRAM, which allows them to commit writes to stable storage quickly, without waiting on the disks. (Note, this is disputed in the NVRAM page).
It is also possible to cluster filers to create a highly-availability cluster with a private high-speed link using either FC or InfiniBand, clusters can then be grouped together under a single namespace when running in the cluster mode of the Data ONTAP 8 operating system.
The filer will be either Intel or AMD processor based computer using PCI, each filer will have a battery-backed NVRAM adaptor to log all writes for performance and to replay in the event of a server crash. The Data ONTAP operating system implements a single proprietary file-system called WAFL (Write Anywhere File Layout).
WAFL is not a filesystem in the traditional sense, but a file layout that supports very large high-performance RAID arrays (up to 100TB), it provides mechanisms that enable a variety of filesystems and technologies that want to access disk blocks. WAFL also offers :
- snapshots (up to 255 per volume can be made)
- snapmirror (disk replication)
- syncmirror (mirror RAID arrays for extra resilience, can be mirrored up to 100km away)
- snaplock (Write once read many, data cannot be deleted until its retention period has been reached)
- read-only copies of the file system
- read-write snapshots called FlexClone
- ACL’s
- quick defragmentation
Source #2
- Reference: NetApp University - Introduction to NetApp Products
At its most basic, data storage supports production; that is, real-time read and write access to a company’s data. Some of this data supports infrastructure applications, such as Microsoft Exchange or Oracle databases, which typically use SAN technologies, FC, and iSCSI. Most environments also have large volumes of file data, such as users’ home directories and departmental shared folders. These files are accessed by using NAS technologies, SMB, and NFS. One of the most important features of the Data ONTAP operating system is its ability to support SAN and NAS technologies simultaneously on the same platform. What once required separate systems with disparate processes is now unified, allowing greater economies of scale and reducing human error.
NetApp Filer
- Reference: Datadisk - NetApp Overview
- Reference: Storage-switzerland - What is a Storage Controller?
The most common NetAPP configuration consists of a filer (also known as a controller or head node) and disk enclosures (also known as shelves), the disk enclosures are connected by Fibre Channel or parallel/serial ATA, the filer is then accessed by other Linux, Unix or Window servers via a network (Ethernet or FC).
Storage arrays all have some form of a processor embedded into a controller. As a result, a storage array’s controller is essentially a server that’s responsible for performing a wide range of functions for the storage system. Think of it as a storage computer. This “computer” can be configured to operate by itself (single controller), in a redundant pair (dual controller) or even as a node within a cluster of servers (scale out storage). Each controller has an I/O path to communicate to the storage network or the directly-attached servers, an I/O path that communicates to the attached storage devices or shelves of devices and a processor that handles the movement of data as well as other data-related functions, such as RAID and volume management.
In the modern data center the performance of the storage array can be directly impacted (and in many cases determined) by the speed and capabilities of the storage controller. The controller’s processing capabilities are increasingly important. There are two reasons for this. The first is the high speed storage infrastructure. The network can now easily send data at 10 Gigabits per second (using 10 GbE) or even 16 Gbps on Fibre Channel. That means the controller needs to be able to process and perform actions on this inbound data at even higher speeds, generating RAID parity for example.
Also the storage system may have many disk drives attached to it and the storage controller has to be able to communicate with each of these. The more drives, the more performance the storage controller has to maintain. Thanks to Solid State Drives (SSD) a very small number of drives may be able to generate more I/O than the controller can support. The controller used to have time between drive I/Os to perform certain functions. With high quantities of drives or high performance SSDs, that time or latency is almost gone.
The second reason that the performance capabilities of the storage controller is important is that the processor on the controller is responsible for an increasing number of complex functions. Besides basic functions, such as RAID and volume management, today’s storage controller has to handle tasks such as:
- snapshots
- clones
- thin provisioning
- auto-tiering
- replication
Snapshots, clones and thin provisioning are particularly burdensome since they dynamically allocate storage space as data is being written or changed on the storage system. This is a very processor-intensive task. The storage system commits to the connecting host that the capacity it expects has already been set aside, and then in the background the storage system works to keep those commitments.
Automated tiering moves data between types or classes of storage so that the most active data is on the fastest type of storage and the least active is on the most cost-effective class of storage. This moving of data back and forth is a lot of work for the controller. Automated tiering also requires that the controller analyze access patterns and other statistics to determine which data should be where. You dont want to promote every accessed file, only files that have reached a certain level of consistent access. The combined functions represent a significant load on the storage processors.
There are, of course, future capabilities that will also require some of the processing power of the controller. An excellent example is deduplication, which is becoming an increasingly popular feature on primary storage. As we expect more from our storage systems the storage controller has an increasingly important role to play, and will have to get faster or be able to be clustered in order to keep up.
From a use perspective it’s important to pay attention to the capabilities of the controller. Does it have enough horsepower to meet your current and future needs? What are the options if you reach the performance limits of the processor? In order to maintain adequate performance as storage systems grow and add CPU-intensive features, companies need to budget for extra ‘headroom’ in their controllers. These systems need to either have plenty of extra headroom, have the ability to add controller processing power or companies should look at one of the scale out storage strategies like The Storage Hypervisor, Scale Out Storage or Grid Storage.
Shelf with Controller Integrated
-
Reference: Mtellin - NetApp Introduces New Controllers
-
Reference: FAS2240: An Inside Look
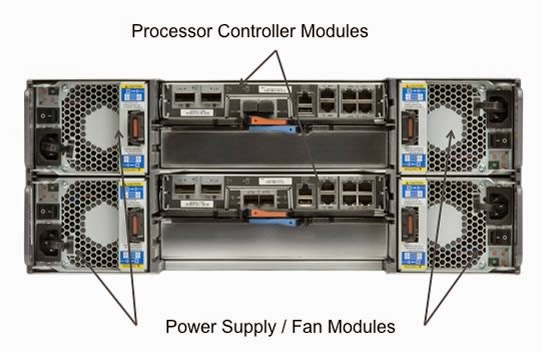
The FAS2240 is a storage shelf with the controllers inserted into the back. The 2240-2 is a 2u system and based on the current FAS2246 SAS shelf, while the 2240-4 is a 4u system and based on the current FAS4243 shelf. The FAS2240-2 utilizes 2.5″ SAS drives and supports either 450 or 600GB drives as of today. The FAS2240-4 utilizes 3.5″ SATA drives and supports 1, 2 or 3TB SATA drives as of today. Both systems can be ordered with either 12 or 24 drives.
If you outgrow your FAS2240-2 or FAS2240-4, you can convert your base chassis into a standard disk shelf by replacing the FAS2240 controller(s) (which we call processor controller modules, or PCMs) with the appropriate I/O modules (IOMs). Connect the converted shelf to a FAS3200 or FAS6200 series storage system without the need to migrate data, and you are back in business with no data migration required and a minimum of downtime.
Rear view of the FAS2240-2 controller

Rear view of the FAS2240-4 controller
Other Posts in this Series
See the NetApp From the Ground Up - A Beginner’s Guide - Index post for links to all of the posts in this series.
As always, if you have any questions or have a topic that you would like me to discuss, please feel free to post a comment at the bottom of this blog entry, e-mail at will@oznetnerd.com, or drop me a message on Reddit (OzNetNerd).
Note: The opinions expressed in this blog are my own and not those of my employer.

Leave a comment