
In my previous post I discussed what a compiler does. In this post I will cover Interpreted code, Bytecode and Just-in-Time compilation. One thing to note at this point is that while a compiler is able to create a standalone executable application (e.g an .exe file in Windows) which does not depend on any other application in order to run, the same is not true for the three methods.
Interpreted Code
When compared to the other options, Interpreters are easiest to comprehend. As this ars article puts it:
Interpreters will include a parsing stage similar to that of the compiler, but this is then used to drive direct execution, with the program being run immediately.
The simplest interpreter has within it executable code corresponding to the various features the language supports—so it will have functions for adding numbers, joining strings, whatever else a given language has. As it parses the code, it will look up the corresponding function and execute it. Variables created in the program will be kept in some kind of lookup table that maps their names to their data.
Further to the above, as this Code Project article puts it:
In some cases, the source code is executed line by line by a software called interpreter. Interpreted languages are often slow than the compiled languages because of a number of reasons. It is because the source should be executed line by line. Also the interpreted languages like python and even Java, C# have a number of advanced facilities like dynamic typing, type checking, extensive type information which would be stored in the interpreter reduces the performance of the interpreted applications. Another disadvantage is that one should have the interpreter installed in the computer unless the interpreter is embedded in the software which may increase the size of the package. For example, Blender has embedded python interpreter.
To sum it up in a couple of sentences, this method provides the slowest performance as it does no pre-compilation. It also requires an Interpreter be installed in order to run the code.
Bytecode
In terms of speed, the next step up from Interpreted code is Bytecode.
Bytecode is a lower level language than the original source code and therefore it runs quicker than the Interpreted option mentioned above. A huge benefit Bytecode has over compiled code is that it is platform and architecture independent. This means that it can run on any CPU architecture without modification. This is made possible through the use of a Virtual Machine (VM) - more on this later.
If you’re using Python and have write access to the directory which contains your script, a Bytecode file (.pyc) will be created when you run your code. This is done so that when you next run your code, the Bytecode file can be used instead of your source code which will result in quicker execution times.
On a side note, because the .pyc file is a complete (optimised) copy of your code, you can actually run it directly instead of using your original .py file.
Having said this, if you do not have write access to the directory, the .pyc is loaded into your computer’s memory and discarded when your script is terminated.
Going back to the Virtual Machines I touched on earlier, as this StackOverflow answer says:
The java virtual machine (JVM) interprets the Byte Code into an instruction that is understandable by the specific architecture the program is running on. There is JVM for every major architecture and operating system so the code you write on Windows will be interpreted and run on MAC-OS or linux without any source level modification by you. That is why Java is portable and that is where the Write Once Run Everywhere motto comes from.
In other words, Bytecode created on a Window system will work on Linux, OSX, etc systems as well without any manual intervention. Note that while the above answer is related to Java, the same is true for all languages which provide a VM.
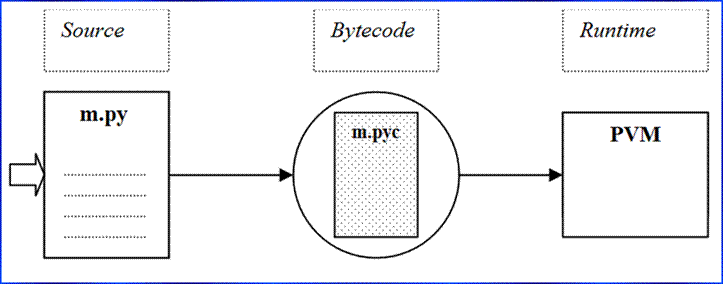
Speaking of which, the Python’s VM is called Python Virtual Machine (PVM). The below illustration from Learning Python shows how source code is translated into Bytecode and then run by the PVM:
Bytecode & Just in Time Compilation (JIT)
“Just In Time” compilers differ from “Ahead of Time” (AOT) in that the former compiles Bytecode while the latter compiles source code. The other difference is that JIT compiles the Bytecode just before your application is run, hence the name “Just in Time”.
Given that JIT compiles its code, it’s easy to see why they’re faster than interpreters who execute their code one line at a time. What might not be so obvious is the fact that JIT can actually be faster than compiled code. You might be wondering: How is that possible given that compiled code is code that is native to the CPU? How can anything be faster than that!?!
Well, the problem with compiled code is that in order to ensure your application works on all CPUs of a specific architecture, e.g 32-bit (x86) or 64-bit (x64), the compiler cannot use processor and/or vendor specific optimisations otherwise it will break compatibility with the CPUs which do not have these features. On the other hand, JIT is able to identify the CPU that’s running the code and implement optimisations which are specific to that chip. This results in better optimisation and therefore faster execution than what you’d see if the code was compiled AOT.
As always, if you have any questions or have a topic that you would like me to discuss, please feel free to post a comment at the bottom of this blog entry, e-mail at will@oznetnerd.com, or drop me a message on Reddit (OzNetNerd).
Note: The opinions expressed in this blog are my own and not those of my employer.

Leave a comment