
Storage
Summary
- Reference: Me :)
Vservers : contain one or more FlexVol volumes, or a single Infinite Volume Volume : is like a partition that can span multiple physical disks LUN : is a big file that is inside the volume. the LUN is what gets presented to the host.
RAID, Volumes, LUNs and Aggregates
Response #1
-
Reference: NetApp Community: Understanding Aggregate And LUN
- An aggregate is the physical storage. It is made up of one or more raid groups of disks.
- A LUN is a logical representation of storage. It looks like a hard disk to the client. It looks like a file inside of a volume.
Raid groups are protected sets of disks. consising of 1 or 2 parity, and 1 or more data disks. We don’t build raid groups, they are built automatically behind the scene when you build an aggregate. For example:
In a default configuration you are configured for RAID-DP and a 16 disk raid group (assuming FC/SAS disks). So, if i create a 16 disk aggregate i get 1 raid group. If I create a 32 disk aggregate, i get 2 raid groups. Raid groups can be adjusted in size. For FC/SAS they can be anywhere from 3 to 28 disks, with 16 being the default. You may be tempted to change the size so i have a quick/dirty summary of reasons.

Aggregates are collections of raid groups. They consist of one or more Raid Groups.
I like to think of aggregates as a big hard drive. There are a lot of similarities in this. When you buy a hard drive you need partition it and format it before it can be used. Until then its basically raw space. Well, thats an aggregate. its just raw space.
A volume is analogous to a partition. It’s where you can put data. Think of the previous analogy. An aggregate is the raw space (hard drive), the volume is the partition, its where you put the file system and data. Some other similarities include the ability to have multiple volumes per aggregate, just like you can have multiple partitions per hard drive. and you can grow and shrink volumes, just like you can grow and shrink partitions.
A qtree is analogous to a subdirectory. Lets continue the analogy. Aggregate is hard drive, volume is partition, and qtree is subdirectory. Why use them? to sort data. The same reason you use them on your personal PC. There are 5 things you can do with a qtree you can’t do with a directory and thats why they aren’t just called directories:
- Oplocks
- Security style
- Quotas
- Snapvault
- Qtree SnapMirror
Last but not least, LUNs. It’s a logical representation of space, off your SAN. But the normal question is when do I use a LUN instead of CIFS or NFS share/export. I normally say it depends on the Application. Some applications need local storage, they just can’t seem to write data into a NAS (think CIFS or NFS) share. Microsoft Exchange and SQL are this way. They require local hard drives. So the question is, how do we take this network storage and make it look like an internal hard drive. The answer is a LUN. It takes a bit of logical space out of the aggregate (actually just a big file sitting in a volume or qtree) and it gets mounted up on the windows box, looking like an internal hard drive. The file system makes normal SCSI commands against it. The SCSI commands get encapsulated in FCP or iSCSI and are sent across the network to the SAN hardware where its converted back into SCSI commands then reinterpreted as WAFL read/writes.
Some applications know how to use a NAS for storage (think Oracle over NFS, or ESX with NFS datastores) and they don’t need LUNs. they just need access to shared space and they can store their data in it.
Response #2
Aggregates are the raw space in your storage system. You take a bunch of individual disks and aggregate them together into aggregates. But, an aggregate can’t actually hold data, its just raw space. You then layer on partitions, which in NetApp land are called volumes. The volumes hold the data.
You make aggregates for various reasons. For example:
- Performance Boundaries - A disk can only be in one aggregate. So each aggregate has its own discreet drives. This lets us tune the performance of the aggregate by adding in however many spindles we need to achieve the type of performance we want. This is kind of skewed by having Flash Cache cards and such, but its still roughly correct.
- Shared Space Boundary - All volumes in an aggregate share the hard drives in that aggregate. There is no way to prevent the volumes in an aggregate from mixing their data on the same drives. I ran into a problem at one customer that, due to regulatory concerns, couldn’t have data type A mixed with data type B. The only way to achieve this is to have two aggregates.
- For volumes - You can’t have a flexible volume without an aggregate. Flex Vols are logical, Aggregates are physical. You layer one or more flex vols on top (in side) of an aggregate.
Response #3
An aggregate is made of Raid Groups.
Lets do a few examples using the command to make an aggregate:
aggr create aggr1 16
If the default raid group size is 16, then the aggregate will have one raid group. But, if i use the command:
aggr create aggr1 32
Now I have two full raid groups, but still only one aggregate. So, the aggregate gets the performance benefit of 2 RGs worth of disks. Notice we did not build a raid group. Data ONTAP built the RG based on the default RG size.
I explain this in more detail in a previous post in this thread.
Response #4
- Volumes are accessed via NAS protocols, CIFS/NFS
- LUNS are accessed via SAN protocols, iSCSI/FCP/FCoE
In the end you can put data in a LUN, you can put data in a Volume. It’s how you get there thats the question.
Response #5
LUNs are logical. They go inside a volume, or in a qtree.
from a NetApp perspective they are really just one big file sitting inside of a volume or qtree.
from a host perspective, they are like a volume, but use a different protocol to access them (purists will argue with that but i’m simplifying). LUNs provide a file system, like Volumes provide a file system, the major difference is who controls the files system. with a LUN the storage system can’t see the file system, all it sees is one big file. The host mounts the file system via one of the previously mentioned protocols and lays a file system down inside. The host then controls that file system.
I normally determine LUN/Volume usage by looking at the Application. Some apps won’t work across a network, Microsoft SQL and Exchange are two examples of this. They require local disks. LUNs look like local disks. Some applications work just fine across the network, using NFS, like Oracle. In the end its normally the application that will determine whether you get your filesystem access through a LUN or a Volume.
some things like Oracle or VMware can use either LUNs or NFS volumes, so with them its whatever you find easier or cheaper.
Response #6
The underlying filesystem is always WAFL in the volume.
when you share out a volume it looks like NTFS to a windows box, or it looks like a UNIX filesystem to a unix box but in the end its just WAFL in the volume.
with a LUN its a bit different.
You first make a volume, then you put a LUN in the volume. the volume has WAFL as the file system, the LUN looks like one big file in the volume.
You then connect to the storage system using a SAN protocol. The big file we call a LUN is attached to the host via the SAN protocol and looks like a big hard drive. The host then formats the hard drive with NTFS or whatever File system the unix box is using. That file system is actually NTFS, or whatever. It’s inside the LUN, which is big file inside of a Volume, which has WAFL as its file system.
Response #7
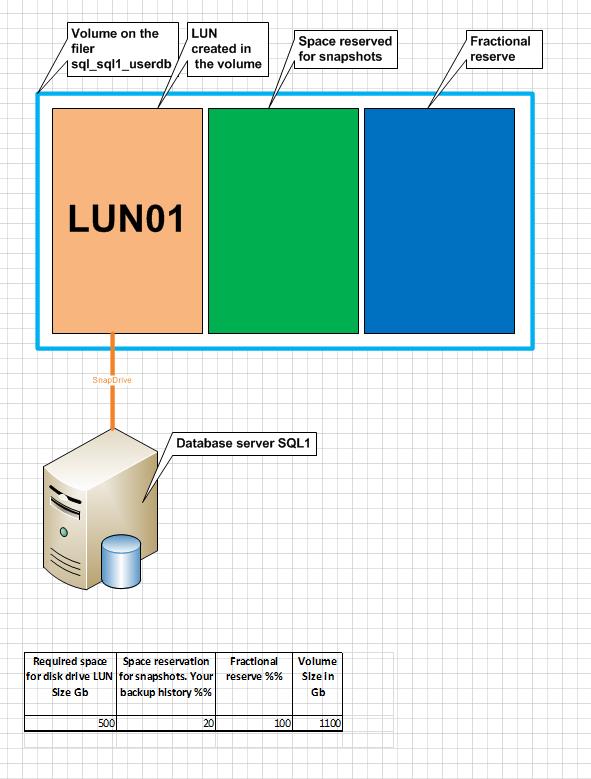
Response #8
You create your volume group (or dynamic disk pool) and volumes (i.e. LUNs) on top of that.
If you have access to Field Portal, you can find more detailed info here:
https://fieldportal.netapp.com/e-series.aspx#150496
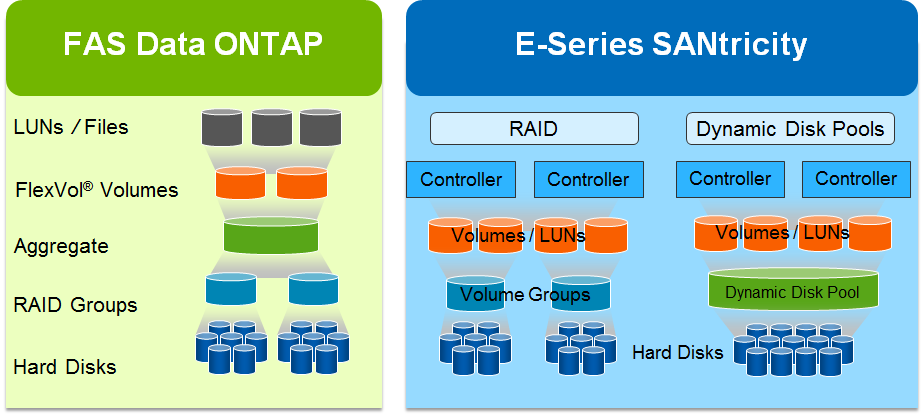
This is a good picture from one of the presos describing the architectural difference between FAS & E-Series:
Qtrees
Overview
- Reference: NetApp
Qtrees represent the third level at which node storage can be partitioned. Disks are organized into aggregates which provides pools of storage. In each aggregate, one or more flexible volumes can be created. Traditional volumes may also be created directly without the previous creation of an aggregate. Each volume contains a file system. Finally, the volume can be divided into qtrees.
Information
- Reference: NetApp
The qtree command creates qtrees and specifies attributes for qtrees.
A qtree is similar in concept to a partition. It creates a subset of a volume to which a quota can be applied to limit its size. As a special case, a qtree can be the entire volume. A qtree is more flexible than a partition because you can change the size of a qtree at any time.
In addition to a quota, a qtree possesses a few other properties.
A qtree enables you to apply attributes such as oplocks and security style to a subset of files and directories rather than to an entire volume.
Single files can be moved across a qtree without moving the data blocks. Directories cannot be moved across a qtree. However, since most clients use recursion to move the children of directories, the actual observed behavior is that directories are copied and files are then moved.
Qtrees represent the third level at which node storage can be partitioned. Disks are organized into aggregates which provides pools of storage. In each aggregate, one or more flexible volumes can be created. Traditional volumes may also be created directly without the previous creation of an aggregate. Each volume contains a file system. Finally, the volume can be divided into qtrees.
If there are files and directories in a volume that do not belong to any qtrees you create, the node considers them to be in qtree 0. Qtree 0 can take on the same types of attributes as any other qtrees.
You can use any qtree command whether or not quotas are enabled on your node.
More Information
- Reference: NetApp Forum
There are 5 things you can do with a qtree you can’t do with a directory and thats why they aren’t just called directories:
- Oplocks
- Security style
- Quotas
- Snapvault
- Qtree SnapMirror
RAID-DP
Understanding RAID-DP disk types
- Reference: Understanding RAID disk types
Data ONTAP classifies disks as one of four types for RAID: data, hot spare, parity, or dParity. The RAID disk type is determined by how RAID is using a disk; it is different from the Data ONTAP disk type.
- Data disk: Holds data stored on behalf of clients within RAID groups (and any data generated about the state of the storage system as a result of a malfunction).
- Spare disk: Does not hold usable data, but is available to be added to a RAID group in an aggregate. Any functioning disk that is not assigned to an aggregate but is assigned to a system functions as a hot spare disk.
- Parity disk: Stores row parity information that is used for data reconstruction when a single disk drive fails within the RAID group.
- dParity disk: Stores diagonal parity information that is used for data reconstruction when two disk drives fail within the RAID group, if RAID-DP is enabled.
RAID Groups and Aggregates
- Reference: RAID Groups and Aggregates
In the course of teaching Netapp’s Data ONTAP Fundamentals course I have noticed that one of the areas that student’s sometimes struggle with are RAID groups as they exist in Data ONTAP.
To begin with, Netapp uses dedicated parity drives, unlike many other storage vendors. Parity information is constructed for a horizontal stripe of WAFL blocks in a RAID group within an aggregate and then written to disk at the same time the data disks are updated. The width of the RAID group – the number of data disks – is independent of the parity disk or disks. Take a look at this print screen from Filerview:
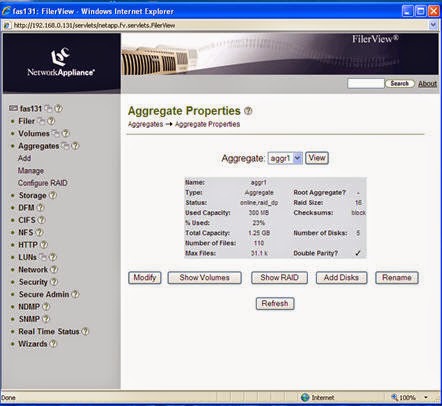
Notice that the RAID group size is 16. This is the default RAID group size for RAID-DP with Fibre Channel disks. Notice also that the number of disk in Aggr1 is actually 5.
When I created aggr1 I used the command:
aggr create aggr1 5
This caused Data ONTAP to create an aggregate named aggr1 with five disks in it. Let’s take a look at this with the following command:
sysconfig –r
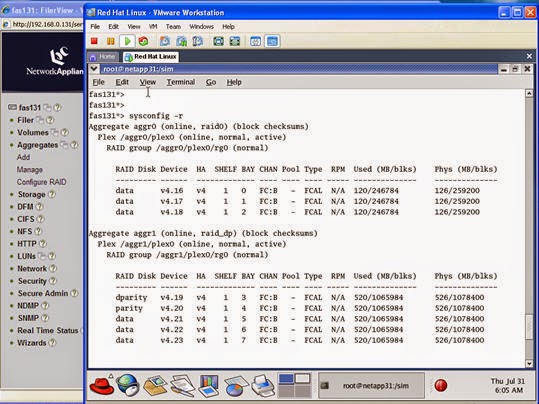
If you notice aggr1, you can see that it contains 5 disks. Three disks are data disks and there are two parity disks, “parity” and “dparity”. The RAID group was created automatically to support the aggregate. I have a partial RAID group in the sense that the RAID group size is 16 (look at the Filerview screen shot). I only asked for an aggregate with 5 disks, so aggr1 has an aggregate with one RAID group and 5 disk drives in it.
It is fully usable in this state. I can create volumes for NAS or SAN use and they are fully functional. If I need more space, I can add disks to the aggregate and they will be inserted into the existing RAID group within the aggregate. I can add 3 disks with the following command:
aggr add aggr1 3
Look at the following output:
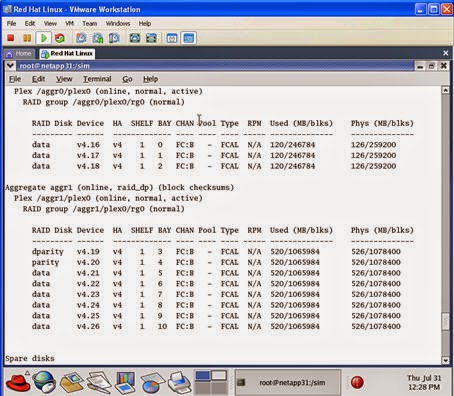
Notice that I have added three more data disks to /aggr1/plex0/rg0.
The same parity disks are protecting the RAID group.
Data ONTAP is able to add disks from the spare pool to the RAID group quickly if the spare disks are pre-zeroed. Before the disks can be added, they must be zeroed. If they are not already zeroed, then Data ONTAP will zero them first. This may take a significant amount of time. Spares as shipped by Netapp are pre-zeroed, but drives that join the spare pool after you destroy and aggregate are not.
The inserted disks are protected by the same parity calculation that existed on the parity drives before they were inserted. This works because the new WAFL blocks that align with the previous WAFL blocks in a parity stripe contain only zeroes. They new (zeroed) disks have no affect on the parity drives.
Once the drives are part of the RAID groups within the aggregate, that space can be made available to volumes and used by applications.
An aggregate can contain multiple RAID groups. If I had created an aggregate with 24 disks, then Data ONTAP would have created two RAID groups. The first RAID group would be fully populated with 16 disks (14 data disks and two parity disks) and the second RAID group would have contained 8 disks (6 data disks and two parity disks). This is a perfectly normal situation.
For the most part, it is safe to ignore RAID groups and simply let Data ONTAP take care of things. The one situation you should avoid however is creating a partial RAID group with only one or two data disks. (Using a dedicated aggregate to support the root volume would be an exception to this rule.) Try to have at least three data disks in a RAID group for better performance.
There is a hierarchy to the way storage is implemented with Data ONTAP. At the base of the hierarchy is the aggregate, which is made up of RAID groups. The aggregate provides the physical space for the flexible volumes (flexvols) that applications see. Applications, whether SAN or NAS, pull space that has been assigned to the volume from the aggregate and are not aware of the underlying physical structure provided by the aggregate.
This is why we say that the aggregate represents the physical storage and the volumes provide the logical storage.
RAID Groups
- Reference: Playing with NetApp … After Rightsizing
Before all the physical hard disk drives (HDDs) are pooled into a logical construct called an aggregate (which is what ONTAP’s FlexVol is about), the HDDs are grouped into a RAID group. A RAID group is also a logical construct, in which it combines all HDDs into data or parity disks. The RAID group is the building block of the Aggregate.
So why a RAID group? Well, first of all, (although likely possible), it is not wise to group a large number of HDDs into a single group with only 2 parity drives supporting the RAID. Even though one can maximize the allowable, aggregated capacity from the HDDs, the data reconstruction or data resilvering operation following a HDD failure (disks are supposed to fail once in a while, remember?) would very much slow the RAID operations to a trickle because of the large number of HDDs the operation has to address. Therefore, it is best to spread them out into multiple RAID groups with a recommended fixed number of HDDs per RAID group.
RAID group is important because it is used to balance a few considerations:
- Performance in recovery if there is a disk reconstruction or resilvering
- Combined RAID performance and availability through a Mean Time Between Data Loss (MTBDL) formula
Different ONTAP versions (and also different disk types) have different number of HDDs to constitute a RAID group. For ONTAP 8.0.1, the table below are its recommendation.
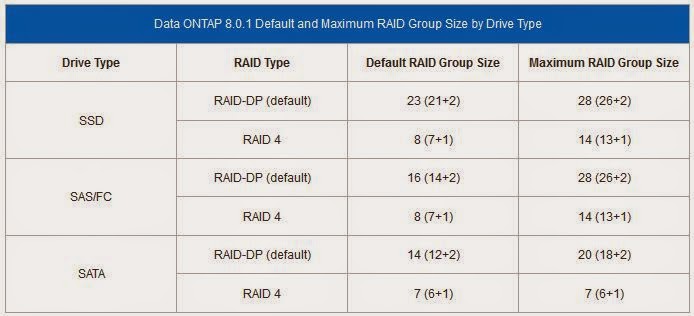
So, given a large pool of HDDs, the NetApp storage administrator has to figure out the best layout and the optimal number of HDDs to get to the capacity he/she wants. And there is also a best practice to set aside 2 hot spare HDDs for a RAID-DP configuration with every 30 or so HDDs so that they can be used in the event of HDD failures. Also, it is best practice to take the default recommended RAID group size most of the time as opposed to the maximum size.
I would presume that this is all getting very confusing, so let me show that with an example. Let’s use the common 2TB SATA HDD and let’s assume the customer has just bought a 100 HDDs FAS6000. From the table above, the default (and recommended) RAID group size is 14. The customer wants to have maximum usable capacity as well. In a step-by-step guide,
-
Consider the hot sparing best practice. The customer wants to ensure that there will always be enough spares, so using the rule-of-thumb of 2 spare HDDs per 30 HDDs, 6 disks are kept aside as hot spares. That leaves 94 HDDs from the initial 100 HDDs.
-
There is a root volume, rootvol, and it is recommended to put this into an aggregate of its own so that it gets maximum performance and availability. To standardize, the storage administrator configures 3 HDDs as 1 RAID group to create the rootvol aggregate, aggr0. Even though the total capacity used by the rootvol is just a few hundred GBs, it is not recommended to place user data into rootvol. Of course, this situation cannot be avoided in most of the FAS2000 series, where a smaller HDDs count are sold and implemented. With 3 HDDs used up as rootvol, the customer now has 91 HDDs.
-
With 91 HDDs, and using the default RAID group size of 14, for the next aggregate of aggr1, the storage administrator can configure 6 x full RAID group of 14 HDDs (6 x 14 = 84) and 1 x partial RAID group of 7 HDDs. (Note that as per this post, there’s nothing wrong with partial RAID groups).
-
RAID-DP requires 2 disks per RAID group to be used as parity disks. Since there are a total of 7 RAID groups from the 91 HDDs, 14 HDDs are parity disks, leaving 77 HDDs as data disks.
This is where the rightsized capacity comes back into play again. 77 x 2TB HDDs is really 77 x 1.69TB = 130.13TB from an initial of 100 x 2TB = 200TB.
If you intend to create more aggregates (in our example here, we have only 2 aggregates – aggr0 and aggr1), there will be more consideration for RAID group sizing and parity disks, further reducing the usable capacity.
More RAID Information
- Reference: Playing with NetApp … final usable capacity
An aggregate, for the uninformed, is the disks pool in which the flexible volume, FlexVol, is derived. In a simple picture below.
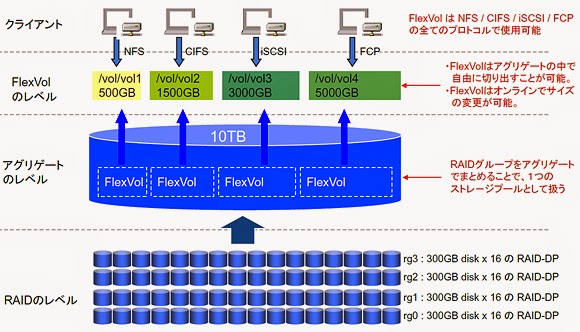
OK, the diagram’s in Japanese (I am feeling a bit cheeky today :P)!
But it does look a bit self explanatory with some help which I shall provide now. If you start from the bottom of the picture, 16 x 300GB disks are combined together to create a RAID Group. And there are 4 RAID Groups created – rg0, rg1, rg2 and rg3. These RAID groups make up the ONTAP data structure called an aggregate. From ONTAP version 7.3 onward, there were some minor changes of how ONTAP reports capacity but fundamentally, it did not change much from previous versions of ONTAP. And also note that ONTAP takes a 10% overhead of the aggregate for its own use.
With the aggregate, the logical structure called the FlexVol is created. FlexVol can be as small as several megabytes to as large as 100TB, incremental by any size on-the-fly. This logical structure also allow shrinking of the capacity of the volume online and on-the-fly as well. Eventually, the volumes created from the aggregate become the next-building blocks of NetApp NFS and CIFS volumes and also LUNs for iSCSI and Fibre Channel. Also note that, for a more effective organization of logical structures from the volumes, using qtree is highly recommended for files and ONTAP management reasons.
However, for both aggregate and the FlexVol volumes created from the aggregate, Snapshot reserve is recommended. The aggregate takes a 5% overhead of the capacity for snapshot reserve, while for every FlexVol volume, a 20% snapshot reserve is applied. While both snapshot percentage are adjustable, it is recommended to keep them as best practice (except for FlexVol volumes assigned for LUNs, which could be adjusted to 0%).
Note: Even if the Snapshot reserve is adjusted to 0%, there are still some other rule sets for these LUNs that will further reduce the capacity. When dealing with NetApp engineers or pre-sales, ask them about space reservations and how they do snapshots for fat LUNs and thin LUNs and their best practices in these situations. Believe me, if you don’t ask, you will be very surprised of the final usable capacity allocated to your applications).
In a nutshell, the dissection of capacity after the aggregate would look like the picture below:
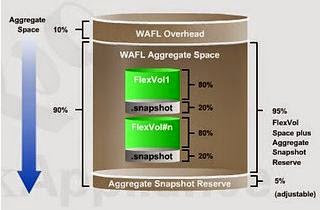
We can easily quantify the overall usable in the little formula that I use for some time:
Rightsized Disks capacity x # Disks x 0.90 x 0.95 = Total Aggregate Usable Capacity
Then remember that each volume takes a 20% Snapshot reserve overhead. That’s what you have got to play with when it comes to the final usable capacity.
Though the capacity is not 100% accurate because there are many variables in play but it gives the customer a way to manually calculate their potential final usable capacity.
Please note the following best practices and this is only applied to 1 data aggregate only. For more aggregates, the same formula has to be applied again.
-
A RAID-DP, 3-disk rootvol0, for the root volume is set aside and is not accounted for in usable capacity
-
A rule-of-thumb of 2-disks hot spares is applied for every 30 disks
-
The default RAID Group size is used, depending on the type of disk profile used
-
Snapshot reserves default of 5% for aggregate and 20% per FlexVol volumes are applied
-
Snapshots for LUNs are subjected to space reservation, either full or fractional. Note that there are considerations of 2x + delta and 1x + delta (ask your NetApp engineer) for iSCSI and Fibre Channel LUNs, even though snapshot reserves are adjusted to 0% and snapshots are likely to be turned off.
Another note to remember is not to use any of those Capacity Calculators given. These calculators are designed to give advantage to NetApp, not necessarily to the customer. Therefore, it is best to calculate these things by hand.
Regardless of how the customer will get as the overall final usable capacity, it is the importance to understand the NetApp philosophy of doing things. While we have perhaps, went overboard explaining the usable capacity and the nitty gritty that comes with it, all these things are done for a reason to ensure simplicity and ease of navigating data management in the storage networking world. Other NetApp solutions such as SnapMirror and SnapVault and also the SnapManager suite of product rely heavily on this.
Right-Sizing
See Part 11 for more information on Right-Sizing.
Other Posts in this Series
See the NetApp From the Ground Up - A Beginner’s Guide - Index post for links to all of the posts in this series.
As always, if you have any questions or have a topic that you would like me to discuss, please feel free to post a comment at the bottom of this blog entry, e-mail at will@oznetnerd.com, or drop me a message on Reddit (OzNetNerd).
Note: The opinions expressed in this blog are my own and not those of my employer.

Leave a comment