
FlexVolume
- Reference: NetApp University - Introduction to NetApp Products
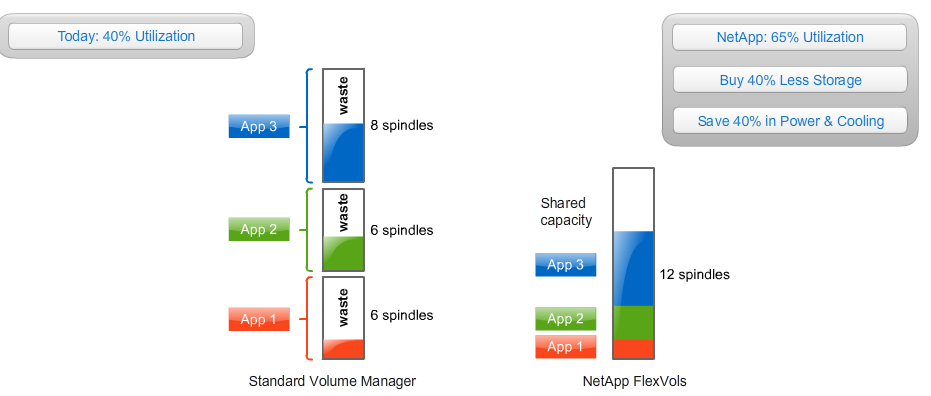
Data production and data protection are the basic capabilities of any storage system. Data ONTAP software goes further by providing advanced storage efficiency capabilities. Traditional storage systems allocate data disk by disk, but the Data ONTAP operating system uses flexible volumes to drive higher rates of utilization and to enable thin provisioning. NetApp FlexVol technology gives administrators the flexibility to allocate storage at current capacity, rather than having to guess at future needs. When more space is needed, the administrator simply resizes the flexible volume to match the need. If the system is nearing its total current capacity, more storage can be added while in production, enabling just-in-time purchase and installation of capacity.
Note: You can’t have a flexible volume without an aggregate.
Infinite Volume
Target Workloads and Use Cases
Infinite Volume was developed to provide a scalable, cost-effective solution for big content workloads. Specifically, Infinite Volume addresses the requirements for large unstructured repositories of primary data, which are also known as enterprise content repositories.
Enterprise content repositories can be subdivided into workloads with similar access patterns, data protection requirements, protocol requirements, and performance requirements.
Infinite Volume is focused on use cases that can be characterized by input/output (I/O) patterns in which data is written once and seldom changed. However, this data is used for normal business operations, and therefore content must be kept online for fast retrieval, rather than being moved to secondary storage.One example of this type of workload is a video file archive. Libraries of large video files are kept in a repository from which they are periodically retrieved and sent to broadcast sites. These repositories typically grow as large as 5PB.
Another example is enterprise content management storage. This can be used to store large amounts of unstructured content such as documents, graphics, and scanned images. These environments commonly can contain a million or more files.
More Information
- Reference: Chucks Blog
Enter the world of vServers and the quintessentially named “infinite volumes”. If you want to do seriously large file systems (like an Isilon normally does), there are some interesting restrictions in play.
In ONTAP 8.1.1 to get meaningfully large file systems, you start with a dedicated hardware/software partition within your 8.1.1 cluster. This partition will support one (and apparently only one) vServer, or visible file system. Between the two constructs exists a new entity: the “infinite volume” – an aggregator of, well, aggregates running on separate nodes.
This “partitioned world” of dedicated hardware, a single vServer and the new infinite volume is the only place where you can start talking about seriously large file systems.
Additional Information
Big content storage solutions can be categorized into three main categories based on the storage, management, and retrieval of the data into file services, enterprise content repositories, and distributed content repositories. NetApp addresses the business challenges of big content by providing the appropriate solution for all of these different environments.
- File services represent the portion of the unstructured data market in which NetApp has traditionally been a leader, including project shares and home directory use cases.
- The enterprise content repository market, by contrast, is less driven by direct end users and more by applications that require large container sizes with an increasing number of files.
- Distributed content repositories take advantage of object protocols to provide a global namespace that spans numerous data centers.
Infinite Volume addresses the enterprise content repository market and is optimized for scale and ease of management. Infinite Volume is a cost-effective large container that can grow to PBs of storage and billions of files. It is built on NetApp’s reliable fabric-attached storage (FAS) and V-Series systems, and it inherits the advanced capabilities of clustered Data ONTAP.
By providing a single large container for unstructured data, e-mail, video, and graphics, Infinite Volume eliminates the need to build data management capabilities into applications with big content requirements. For these environments, Infinite Volume takes advantage of native storage efficiency features, such as deduplication and compression, to keep storage costs low.
Further, since Infinite Volume is built into clustered Data ONTAP, the customer is able to host both Infinite Volume(s) and FlexVol volumes together in a unified scale-out storage solution. This provides the customer with the ability to host a variety of different applications in a multi-tenancy environment, with nondisruptive operations and the ability to use both SAN and NAS in the same storage infrastructure leveraging the same hardware.
Advantages of Infinite Volume
Infinite Volume offers many business advantages for enterprise content repositories. For example, an Infinite Volume for an enterprise content repository solution can be used to:
- Reduce the cost of scalability
- Lower the effective cost per GB
- Efficiently ingest, store, and deliver large amounts of data
- Reduce complexity and management overhead
- Simplify and automate storage management operations
- Provide seamless operation and data and service availability
Infinite Volume leverages dense storage shelves from NetApp with the effective use of large-capacity storage disks. The solution is built on top of the proven foundation of Data ONTAP with storage efficiency features like deduplication and compression.
Infinite Volume gives customers a single, large, scalable container to help them manage huge amounts of growth in unstructured data that might be difficult to manage by using several containers. Data is automatically load balanced across the Infinite Volume at ingest. This manageability allows storage administrators to easily monitor the health state and capacity requirements of their storage systems.
Infinite Volumes are configured within a Data ONTAP cluster and do not require dedicated hardware. Infinite Volumes can share the same hardware with FlexVol volumes.
Overview of Infinite Volume
NetApp Infinite Volume is a software abstraction hosted over clustered Data ONTAP. It provides a single mountpoint that can scale to 20PB and 2 billion files, and it integrates with NetApp’s proven technologies and products, such as deduplication, compression, and NetApp SnapMirror® replication technology.
Infinite Volume writes an individual file in its entirety to a single node but distributes the files across several controllers within a cluster.
Figure 1 shows how an Infinite Volume appears as a single large container with billions of files stored in numerous data constituents.
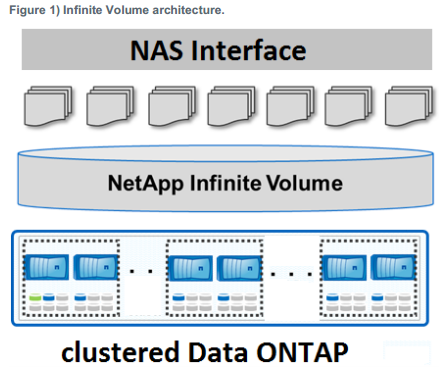
In the first version of Infinite Volume, data access was provided over the NFSv3 protocol. Starting in clustered Data ONTAP 8.2, Infinite Volume added support for NFSv4.1, pNFS, and CIFS. Like a FlexVol volume, Infinite Volume data is protected by using NetApp Snapshot, Raid-DP, and SnapMirror technologies, and NFS or CIFS mounted tape backups.
FlexVol Vs Infinite Vol
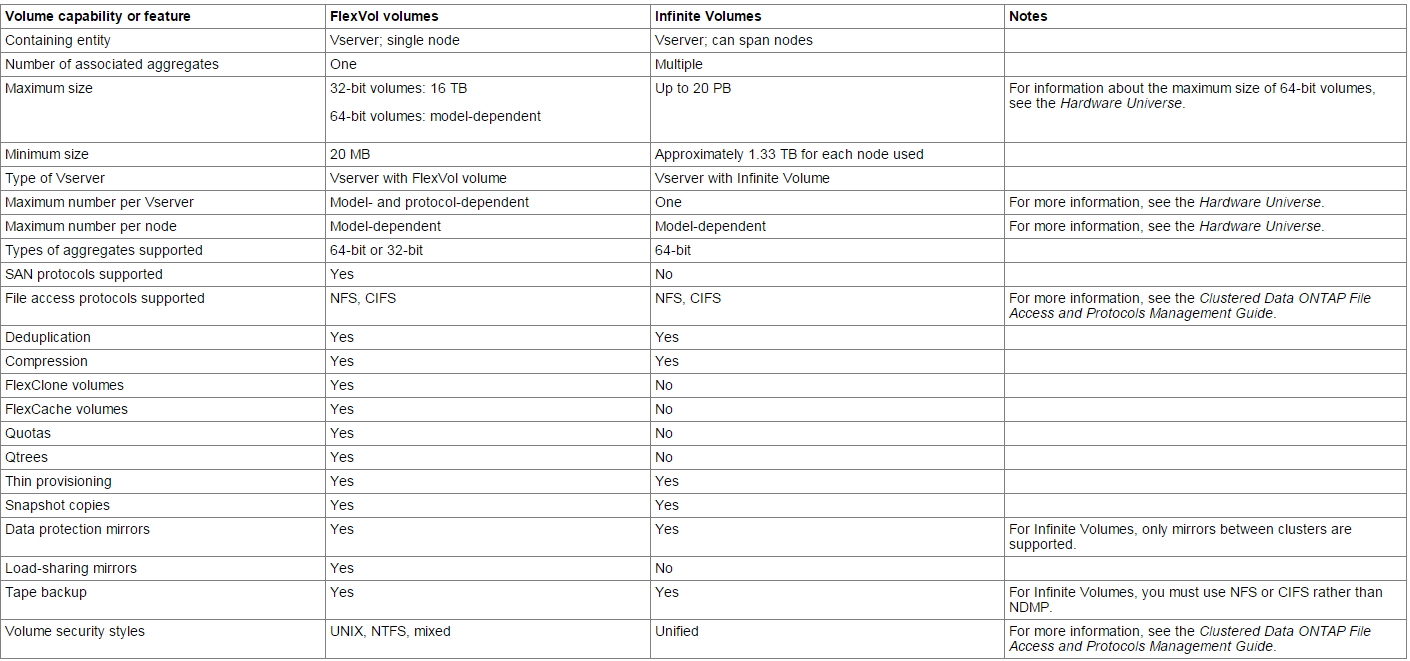
Both FlexVol volumes and Infinite Volumes are data containers. However, they have significant differences that you should consider before deciding which type of volume to include in your storage architecture.
The following table summarizes the differences and similarities between FlexVol volumes and Infinite Volumes:
FlexClone
- Reference: Back to Basics: FlexClone
In the IT world, there are countless situations in which it is desirable to create a copy of a dataset: Application development and test (dev/test) and the provisioning of new virtual machines are common examples. Unfortunately, traditional copies don’t come free. They consume significant storage capacity, server and network resources, and valuable administrator time and energy. As a result, your operation probably makes do with fewer, less up-to-date copies than you really need.
This is exactly the problem that NetApp FlexClone technology was designed to solve. FlexClone was introduced to allow you to make fast, space-efficient copies of flexible volumes (FlexVol volumes) and LUNs. A previous Tech OnTap article describes how one IT team used the NetApp rapid cloning capability built on FlexClone technology (now incorporated as part of the NetApp Virtual Storage Console, or VSC) to deploy a 9,000-seat virtual desktop environment with flexible, fast reprovisioning and using a fraction of the storage that would normally be required. NetApp uses the same approach for server provisioning in its own data centers.
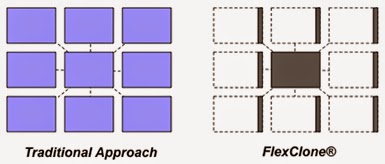
Figure 1 FlexClone technology versus the traditional approach to data copies.
Using FlexClone technology instead of traditional copies offers significant advantages. It is:
- Fast. Traditional copies can take many minutes or hours to make. With FlexClone technology even the largest volumes can be cloned in a matter of seconds.
- Space efficient. A clone uses a small amount of space for metadata, and then only consumes additional space as data is changed or added.
- Reduces costs. FlexClone technology can cut the storage you need for dev/test or virtual environments by 50% or more.
- Improves quality of dev/test. Make as many copies of your full production dataset as you need. If a test corrupts the data, start again in seconds. Developers and test engineers spend less time waiting for access to datasets and more time doing productive work.
- Lets you get more from your DR environment. FlexClone makes it possible to clone and fully test your DR processes, or use your DR environment for dev/test without interfering with ongoing replication. You simply clone your DR copies and do dev/test on the clones.
- Accelerates virtual machine and virtual desktop provisioning. Deploy tens or hundreds of new VMs in minutes with only a small incremental increase in storage.
Most Tech OnTap readers probably know about the use of FlexClone for cloning volumes. What’s less well known is that, starting with Data ONTAP 7.3.1, NetApp also gave FlexClone the ability to clone individual files and improved the capability for cloning LUNs.
This chapter of Back to Basics explores how NetApp FlexClone technology is implemented, the most common use cases, best practices for implementing FlexClone, and more.
Other Posts in this Series
See the NetApp From the Ground Up - A Beginner’s Guide - Index post for links to all of the posts in this series.
As always, if you have any questions or have a topic that you would like me to discuss, please feel free to post a comment at the bottom of this blog entry, e-mail at will@oznetnerd.com, or drop me a message on Reddit (OzNetNerd).
Note: The opinions expressed in this blog are my own and not those of my employer.
