
Backups
- Reference: NetApp Training - Fast Track 101: NetApp Portfolio
Affordable NetApp protection software safeguards your data and business-critical applications.
Explore the range of NetApp protection software products available to protect your valuable data and applications and to provide optimal availability, IT efficiency, and peace of mind.
We have a number of different types of data protection applications - they are:
- Disk-to-Disk - Back up and Recovery Solutions
- Application-Aware - Backup and Recovery Solutions for Application and Backup Admins
- Business continuity - High Availability SolutionsLet’s look at these in detail.
Disk-to-Disk Backup and Recovery Solutions
-
Reference: NetApp Training - Fast Track 101: NetApp Portfolio
- Disk-to-Disk Back up and Recovery Solutions
- SnapVault software speeds and simplifies backup and data recovery, protecting data at the block level.
- Open Systems SnapVault (OSSV) software leverages block-level incremental backup technology to protect Windows, Linux, UNIX, SQL Server, and VMware systems running on mixed storage.
- SnapRestore data recovery software uses stored Data ONTAP Snapshot copies to recover anything from a single file to multi-terabyte volumes, in seconds.
Application-Aware Backup and Recovery Solutions for Application and Backup Administrators
-
Reference: NetApp Training - Fast Track 101: NetApp Portfolio
- Application-Aware Backup and Recovery Solutions for Application and Backup Admins
- The SnapManager management software family streamlines storage management and simplifies configuration, backup, and restore operations.
- SnapProtect management software accelerates and simplifies backup and data recovery for shared IT infrastructures.
- OnCommand Unified Manager automates the management of physical and virtual storage for NetApp storage systems and clusters.
Business Continuity and High Availability Solutions
-
Reference: NetApp Training - Fast Track 101: NetApp Portfolio
- Business continuity and High Availability Solutions
- SnapMirror data replication technology provides disaster recovery protection and simplifies the management of data replication.
- MetroCluster high-availability and disaster recovery software delivers continuous availability, transparent failover protection, and zero data loss.
Snapshot
Basic Snapshots
- Reference: Why NetApp Snapshots Are Awesome
In the beginning, snapshots were pretty simple: a backup, only faster. Read everything on your primary disk, and copy it to another disk.
Simple. Effective. Expensive.
Think of these kinds of snapshots as being like a photocopier. You take a piece of paper, and write on it. When you want a snapshot, you stop writing on the paper, put it into the photocopier, and make a copy. Now you have 2 pieces of paper.
A big database might take up 50 pieces of paper. Taking a snapshot takes a while, because you have to copy each page. And the cost adds up. Imagine each piece of paper cost $5k, or $10k.
Still, it’s faster than hand-copying your address book into another book every week.
It’s not a perfect analogy, but it’s pretty close.
Copy-on-Write Snapshots
- Reference: Why NetApp Snapshots Are Awesome
Having to copy all the data every time is a drag, because it takes up a lot of space, takes ages, and costs more. Both taking the snapshot, and restoring it, take a long time because you have to copy all the data.
But what if you didn’t have to? What if you could copy only the bits that changed?
Enter copy-on-write snapshots. The first snapshot records the baseline, before anything changes. Since nothing has changed yet, you don’t need to move data around.
But as soon as you want to change something, you need to take note of it somewhere. Copy-on-write does this by first copying the original data to a (special, hidden) snapshot area, and then overwriting the original data with the new data. Pretty simple, and effective.
And now it doesn’t take up as much space, because you’re just recording the changes, or deltas.
But there are some downsides.
Each time you change a block of data, the system has to read the old block, write it to the snapshot area, and then write the new block. So, for each write, the disk actually does two writes and one read. This slows things down.
It’s a tradeoff. You lose a bit in write performance, but you don’t need as much disk to get snapshots. With some clever cacheing and other techniques, you can reduce the performance impact, and overall you save money but get some good benefits, so it was often worth it.
But what if you didn’t have to copy the original data?
NetApp Snapshots
- Reference: Why NetApp Snapshots Are Awesome
NetApp snapshots (and ZFS snapshots, incidentally) do things differently. Instead of copying the old data out of the way before it gets overwritten, the NetApp just writes the new information to a special bit of disk reserved for storing these changes, called the SnapReserve. Then, the pointers that tell the system where to find the data get updated to point to the new data in the SnapReserve.
That’s why the SnapReserve fills up when you change data on a NetApp. And remember that deleting is a change, so deleting a bunch of data fills up the SnapReserve, too.
This method has a bunch of advantages. You’re only recording the deltas, so you get the disk savings of copy-on-write snapshots. But you’re not copying the original block out of the way, so you don’t have the performance slowdown. There’s a small performance impact, but updating pointers is much faster, which is why NetApp performance is just fine with snapshots turned on, so they’re on by default.
It gets better.
Because the snapshot is just pointers, when you want to restore data (using SnapRestore) all you have to do is update the pointers to point to the original data again. This is faster than copying all the data back from the snapshot area over the original data, as in copy-on-write snapshots.
So taking a snapshot completes in seconds, even for really large volumes (like, terabytes) and so do restores. Seconds to snap back to a point in time. How cool is that?
Snapshots Are Views
- Reference: Why NetApp Snapshots Are Awesome
It’s much better to think of snapshots as a View of your data as it was at the time the snapshot was taken. It’s a time machine, letting you look into the past.
Because it’s all just pointers, you can actually look at the snapshot as if it was the active filesystem. It’s read-only, because you can’t change the past, but you can actually look at it and read the data.
This is incredibly cool.
Seriously. It’s amazing. You get snapshots with almost no performance overhead, and you can browse through the data to see what it looked like yesterday, or last week, or last month. Online.
So if you accidentally delete a file, you don’t have to restore the entire G:, or suck the data off a copy on tape somewhere. You can just wander through the .snapshot (or ~snapshot) directory and find the file, and read it. You can even copy it back out into the active file system if you want.
All without ringing the helpdesk.
inodes & pointers
- Reference: NetApp snapshots
Snapshot is the point in time of copy of a volume/file system. Snapshots are useful for backup and recovery purposes. With snapshot technology the file system/volume can be backed up within a matter of few seconds. With traditional backups to tape, recovery of file/directory involves checking the media onto which backup was written, loading that media into tape library and restoring the file. This process takes long time and in some cases users/application developers needs the file urgently to complete their tasks. With snapshot technology the snapshot of a file/volume stores in the system itself and administrator can restore the file within a fraction of seconds which helps users to complete their tasks.
How snapshot works
Snapshot copies the file system/volume when requested to do so. If we have to copy all the data in file system/volume using traditional OS mechanisms, it takes a lot of time and consumes lot of space in system. Snapshots overcome this problem by copying only the blocks that have changed. This is explained below.
If we take a snapshot of a file system/volume, no new data is created or new space is consumed in the system. Instead of this system copies the inode information of the file system to snapshot volume. inode information consists of:
- file permissions
- owner
- group
- access/modification times
- pointers to data blocks
- etc
The inode pointers of snapshot volume point to same data blocks of the file system for which snapshot created. In this way snapshot consumes very minimal space (metadata of original file system).
What happens if block has been changed in original file system? Before changing the data block, system copies the data block to snapshot area and overwrites the original data block with new data. Inode pointer will be updated in snapshot to point to the data block that is written in snapshot area. In this manner, changing the data block involves reading the original data block (read operation), writing it to snapshot area and overwriting the original data block with new data (two write operations). This causes performance degradation to some extent. But you don’t need much disk space with this method, as we will record only the changes made to file system/volume. This is called Copy-On-Write (COW) snapshot.
Now we will see how Netapp does it differently.
While changing the block in volume with snapshot created, instead of copying the original block to snapshot area, Netapp writes the new volume to snapreserve space. This involves only one write instead of two writes and one read with COW snapshot. However this also has some performance impact as this involves the changing the inode pointers of file system/volume, but this is minimal if compared to CO which is why Netapp snapshot method is superior when compared to other vendor snapshots.
Also during restores also, Netapp changes the pointers of filesystem to snapshot block. With COW snapshot we need to copy the file from snapshot volume to original volume. So restore with NetApp if faster when compared to COW snapshots.
Thus Netapp snapshot methodology is superior and faster compared to COW snapshots.
SnapVault
- Reference: NetApp Training - Fast Track 101: NetApp Portfolio
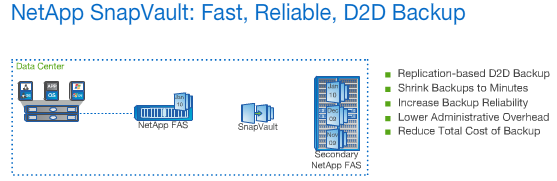
Snapshot copies are stored on the local disk to enable fast backup and fast recovery. But what if the local disk goes offline or fails? NetApp SnapVault software protects against this type of failure and enables long-term backup and recovery. SnapVault software delivers disk-to-disk backup, protecting NetApp primary storage by replicating Snapshot copies to inexpensive secondary storage. SnapVault software replicates only new or changed data using Snapshot copies, and stores the data in native format, keeping both backup and recovery times short and minimizing the storage footprint on secondary storage systems.
SnapVault software can be used to store months or even years of backups, so that fewer tape backups are needed and recovery times stay short. As with the rest of the NetApp Integrated Data Protection portfolio, SnapVault software uses deduplication to further reduce capacity requirements and overall backup costs. SnapVault software is available to all NetApp storage systems that run the Data ONTAP operating system.
More Information
- Reference: NetApp SnapVault
Providing speed and simplicity for data backup and recovery, NetApp SnapVault software leverages block-level incremental replication and NetApp Snapshot copies for reliable, low-overhead disk-to-disk (D2D) backup.
NetApp’s flagship D2D backup solution, SnapVault provides efficient data protection by copying only the data blocks that have changed since the last backup, instead of entire files. As a result, you can back up more frequently while reducing your storage footprint, because no redundant data is moved or stored. And with direct backups between NetApp systems, SnapVault D2D minimises the need for external infrastructure and appliances.
By changing the backup paradigm, NetApp SnapVault software simplifies your adaptation to data growth and virtualisation, and it streamlines the management of terabytes to petabytes of data. Use the SnapVault backup solution as a part of NetApp’s integrated data protection approach to help create a flexible and efficient shared IT infrastructure.
By transferring only new or changed blocks of data, traditional backups which would usually take hours or days to complete, only take minutes. Further to this, it also enables you to store months or years of Point-in-Time Backup Copies on disk. When used in conunction with deduplication, Tape backups are reduced or even eliminated.
Backups can be used for:
- Development and Testing
- Reporting
- Cloning
- DR Replication
SnapMirror
Summary
SnapMirror is a volume level replication, which normally works over IP network (SnapMirror can work over FC but only with FC-VI cards and it is not widely used).
- SnapMirror Asynchronous replicates data according to schedule.
- SnapMirror Sync uses NVLOGM shipping (described briefly in my previous post) to synchronously replicate data between two storage systems.
- SnapMirror Semi-Sync is in between and synchronizes writes on Consistency Point (CP) level.
SnapMirror provides protection from data corruption inside a volume. But with SnapMirror you don’t have automatic failover of any sort. You need to break SnapMirror relationship and present data to clients manually. Then resynchronize volumes when problem is fixed.
Information
- Reference: NetApp Training - Fast Track 101: NetApp Portfolio
Because customers require 24×7 operations, they must protect business applications and virtual infrastructures from site outages and other disasters.
SnapMirror software is the primary NetApp data protection solution. It is designed to reduce the risk, cost, and complexity of disaster recovery. It protects customers’ business-critical data and enables customers to use their disaster recovery sites for other business activities which greatly increases the utilization of valuable resources. SnapMirror software is for disaster recovery and business continuity, whereas SnapVault software is for long-term retention of point-in-time backup copies.
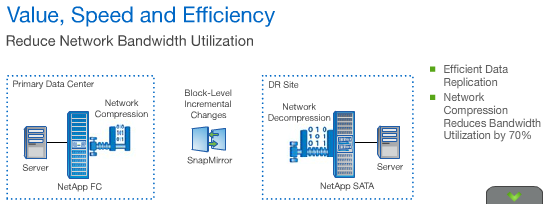
SnapMirror software is built into the Data ONTAP operating system, enabling a customer to build a flexible disaster recovery solution. SnapMirror software replicates data over IP or Fibre Channel to different models of NetApp storage and to storage not produced by NetApp but managed by V Series systems. SnapMirror software can use deduplication and built-in network compression to minimize storage and network requirements, which reduces costs and accelerates data transfers.
Customers can also benefit from SnapMirror products if they have virtual environments, regardless of the vendors they use. NetApp software integrates with VMware, Microsoft Hyper-V, and Citrix XenServer to enable simple failover when outages occur.
More Information
- Reference: NetApp SnapMirror Data Replication
SnapMirror data replication leverages NetApp unified storage to turn disaster recovery into a business accelerator.
Built on NetApp’s unified storage architecture, NetApp SnapMirror technology provides fast, efficient data replication and disaster recovery (DR) for your critical data, to get you back to business faster.
With NetApp’s flagship data replication product, use a single solution across all NetApp storage arrays and protocols, for any application, in both virtual and traditional environments, and in a variety of configurations. Tune SnapMirror technology to meet recovery point objectives ranging from zero seconds to hours.
Cost-effective SnapMirror capabilities include new network compression technology to reduce bandwidth utilization; accelerated data transfers to lower RPO; and improved storage efficiency in a virtual environment using NetApp deduplication. Integrated with FlexClone volumes for instantaneous, space-efficient copies, SnapMirror software also lets you use replicated data for DR testing, business intelligence, and development and test—without business interruptions.
Combine SnapMirror with NetApp MultiStore and Provisioning Manager software to gain application transparency with minimal planned downtime.
Disaster Recovery
- Reference: NetApp Training - Fast Track 101: NetApp Portfolio
In addition to enabling rapid, cost-effective disaster recovery, SnapMirror software simplifies testing of disaster recovery processes to make sure they work as planned - before an outage occurs. Typically, testing is painful for organizations. Companies must bring in people on weekends, shut down production systems, and perform a failover to see if applications and data appear at the remote site. Studies indicate that disaster recovery testing can negatively impact customers and their revenues and that one in four disaster recovery tests fail.
Because of the difficulty of testing disaster recovery, many customers do not perform the testing that is necessary to ensure their safety. With SnapMirror products and FlexClone technology, customers can test failover any time without affecting production systems or using much storage.
To test failover with SnapMirror products and FlexClone technology, a customer first creates space-efficient copies of disaster recovery data instantaneously. The customer uses the copies for testing. After finishing testing, the customer can delete the clones in seconds.
SnapVault Vs SnapMirror
When I was getting into NetApp I had a big trouble understanding the difference between snapvault and snapmirror. I heard an explanation: Snapvault is a backup solution where snapmirror is a DR solution. And all I could do was say ‘ooh, ok’ still not fully understanding the difference…
The first idea that popped out to my head was that snapmirror is mainly set on volume level, where snapvault is on qtree level. But that is not always the case, you can easily setup QSM (Qtree snapmirror).
The key to understanding the difference is really understand the sentence: Snapvault is a backup solution where snapmirror is a DR solution.
What does it mean that SnapVault is a backup solution?
Let me bring some picture to help me explain:
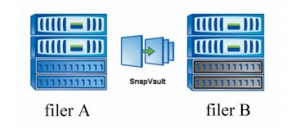 Example has few assumptions:
Example has few assumptions:
- We’ve got filerA in one location and filerB in other location
- That customer has a connection to both filerA and FilerB, although all shares to customers are available from filerA (via CIFS, NFS, iSCSI or FC)
- All customer data is being transfered to the filerB via Snapvault
What we can do with snapvault?
- As a backup solution, we can have a longer snapshot retention time on filerB, so more historic data will be available on filerB, if filerB has slower disks, this solution is smart, because slower disk = cheaper disks, and there is no need to use 15k rpm disk on filer that is not serving data to the customer.
- If customer has an network connection and access to shares on filerB he can by himself restore some data to filerA, even single files
- If there is a disaster within filerA and we loose all data we can restore the data from filerB
What we cannot do with snapvault?
- In case of an disaster within filerA we cannot “set” filerB as a production side. We cannot “revert the relationship” making the qtree on filerB as a source, and make them read/write. They are Snapvault destinations so they are read-only.
- (Having snapmirror license available on filerB we can convert Snapvault qtree to snapmirror qtree which solves that ‘issue’).
What does it mean that SnapMirror is a DR solution?
Again, let me bring the small picture to help me explain:
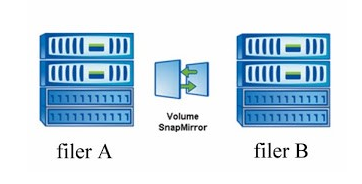 Example has few assumptions:
Example has few assumptions:
- We’ve got filerA in one location and filerB in other location
- That customer has a connection to both filerA and FilerB, although all shares to customers are available from filerA
- All customer data is being transfered to the filerB via snapmirror
What we can do with snapmirror?
- As a backup solution we can restore the accidentally deleted, or lost data on filerA, if the snapmirror relationship has not been updated meantime
- If there is some kind or issue with filerA (from a network problem, to a total disaster) we can easily reverse the relationship. We can make the volume or qtree on filerB, as a source, and make it read-write, provide an network connection to the customer and voila – we are back online! After the issue has been solved we can resync the original source with changes made at the destination and reverse the relationship again.
To sum up
This is not the only difference between snapmirror and snapvault. But I would say this is the main one. Some other differences are that snapmirror can be actually in sync or semi-sync mode. The async mode can be updated even once a minute. Where the snapvault relationship cannot be updated more often then once an hour. If we have few qtrees on the same volume with snapvault they share the same schedule, while with QSM they can have different schedules, etc.. ;)
More Information
If you would like to know more check out this document: SnapVault Best Practices Guide
Also see this page for more information.
Other Posts in this Series
See the NetApp From the Ground Up - A Beginner’s Guide - Index post for links to all of the posts in this series.
As always, if you have any questions or have a topic that you would like me to discuss, please feel free to post a comment at the bottom of this blog entry, e-mail at will@oznetnerd.com, or drop me a message on Reddit (OzNetNerd).
Note: The opinions expressed in this blog are my own and not those of my employer.
