
SyncMirror
Summary
SyncMirror mirror aggregates and work on a RAID level. You can configure mirroring between two shelves of the same system and prevent an outage in case of a shelf failure.
SyncMirror uses a concept of plexes to describe mirrored copies of data. You have two plexes: plex0 and plex1. Each plex consists of disks from a separate pool: pool0 or pool1. Disks are assigned to pools depending on cabling. Disks in each of the pools must be in separate shelves to ensure high availability. Once shelves are cabled, you enable SyncMiror and create a mirrored aggregate using the following syntax:
aggr create aggr_name -m -d disk-list -d disk-list
Plexes
SyncMirror mirror aggregates and work on a RAID level. You can configure mirroring between two shelves of the same system and prevent an outage in case of a shelf failure.
SyncMirror uses a concept of plexes to describe mirrored copies of data. You have two plexes: plex0 and plex1. Each plex consists of disks from a separate pool: pool0 or pool1. Disks are assigned to pools depending on cabling. Disks in each of the pools must be in separate shelves to ensure high availability.
Plex & Disk Pools
- Reference: NetApp Forum: What Is A Disk Pool?
By default Data ONTAP without syncmirror license will keep all disks in pool0 (default). So you will have only one plex.
You need to have syncmirror license to get two plexes, which will enable RAID-level mirroring on your storage system.
The following Filerview online help will give more information in this.
Managing Plexes
The SyncMirror software creates mirrored aggregates that consist of two plexes, providing a higher level of data consistency through RAID-level mirroring. The two plexes are simultaneously updated; therefore, the plexes are always identical.
When SyncMirror is enabled, all the disks are divided into two disk pools, and a copy of the plex is created. The plexes are physically separated, (each plex has its own RAID groups and its own disk pool), and the plexes are updated simultaneously. This provides added protection against data loss if there is a double-disk failure or a loss of disk connectivity, because the unaffected plex continues to serve data while you fix the cause of the failure. Once the plex that has a problem is fixed, you can resynchronize the two plexes and reestablish the mirror relationship.
You can create a mirrored aggregate in the following ways:
- You can create a new aggregate that has two plexes.
- You can add a plex to an existing, unmirrored aggregate.
An aggregates cannot have more than two plexes.
Note: Data ONTAP names the plexes of the mirrored aggregate. See the Data ONTAP Storage Management Guide for more information about the plex naming convention.
How Data ONTAP selects disks
Regardless of how you create a mirrored aggregate, Data ONTAP determines which disks to use. Data ONTAP uses the following disk-selection policies when selecting disks for mirrored aggregates:
- Disks selected for each plex must come from different disk pools.
- The number of disks selected for one plex must equal the number of disks selected for the other plex.
- Disks are first selected on the basis of equivalent bytes per sector (bps) size, then on the basis of the size of the disk.
- If there is no equivalent-sized disk, Data ONTAP selects a larger-capacity disk and uses only part of the disk.
Disk selection policies if you select disks
Data ONTAP enables you to select disks when creating or adding disks to a mirrored aggregate. You should follow the same disk-selection policies that Data ONTAP follows when selecting disks for mirrored aggregates. See the Data ONTAP Storage Management Guide for more information
More Information
-
Reference: NetApp Forum: What Is A Plex
-
Diagram: NetApp
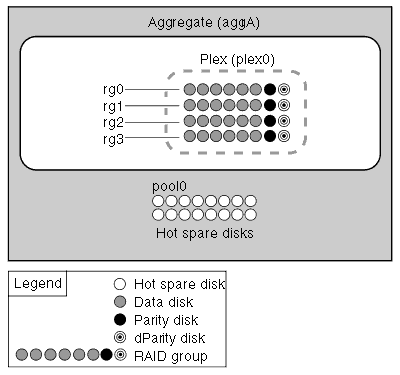
A plex is a complete copy of an aggregate. If you do not have mirroring enabled, you’ll only be using Plex0. If you enabling mirroring, Plex1 will be created. Plex1 will synchornise with Plex0 so you will have two complete copies of the one aggregate. This provides full redundancy should Plex0’s shelf go off line or suffer a multi-disk failure.
- SyncMirror protects against data loss by maintaining two copies of the data contained in the aggregate, one in each plex.
- A plex is one half of a mirror (when mirroring is enabled). Mirrors are used to increase fault tolerance. A mirror means, that whatever you write on one disk gets written on a second disk - at least that is the general idea- immediately. Thus mirroring is a way to prevent data loss from loosing a disk.
- If you do not mirror, there is no reason to call the disk in an aggregate a plex really. But it is easier - for consistency etc.- to call the first bunch of disks that make up an aggregate plex 0. Once you decide to make of mirror -again to ensure fault tolerance- you need the same amount of disks the aggregate is made of for the second half of the mirror. This second half is called plex1.
- So bottom-line, unless you mirror an aggregate, plex0 is just a placeholder that should remind you of the ability to create a mirror if needed.
- By default all your raidgroups will be tied towards plex0, the moment you enable syncmirror things will change. After enabling the syncmirror license you move disks from default pool pool0 to pool1. Then when you syncmirror your aggregate you will find pool0 disks will be tied with plex0 and pool1 will be under plex1.
- A plex is a physical copy of the WAFL storage within the aggregate. A mirrored aggregate consists of two plexes; unmirrored aggregates contain a single plex.
- A plex is a physical copy of a filesystem or the disks holding the data. A DataONTAP volume normally consists of one plex. A mirrored volume has two or more plexes, each with a complete copy of the data in the volume. Multiple plexes provides safety for your data as long as you have one complete plex, you will still have access to all your data.
- A plex is a physical copy of the WAFL storage within the aggregate. A mirrored aggregate consists of two plexes; unmirrored aggregates contain a single plex. In order to create a mirrored aggregate, you must have a filer configuration that supports RAID-level mirroring. When mirroring is enabled on the filer, the spare disks are divided into two disk pools. When an aggregate is created, all of the disks in a single plex must come from the same disk pool, and the two plexes of a mirrored aggregate must consist of disks from separate pools, as this maximizes fault isolation.
Protection provided by RAID and SyncMirror
- Reference: Protection provided by RAID and SyncMirror
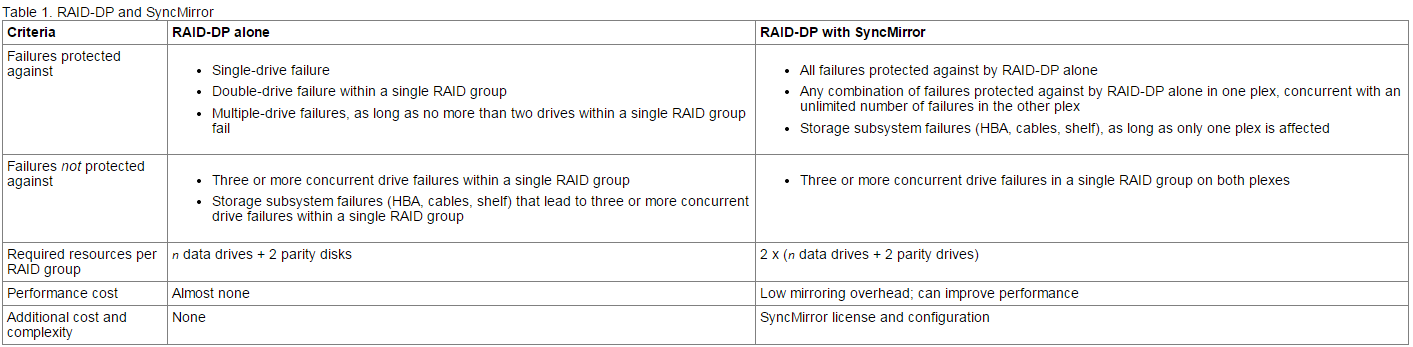
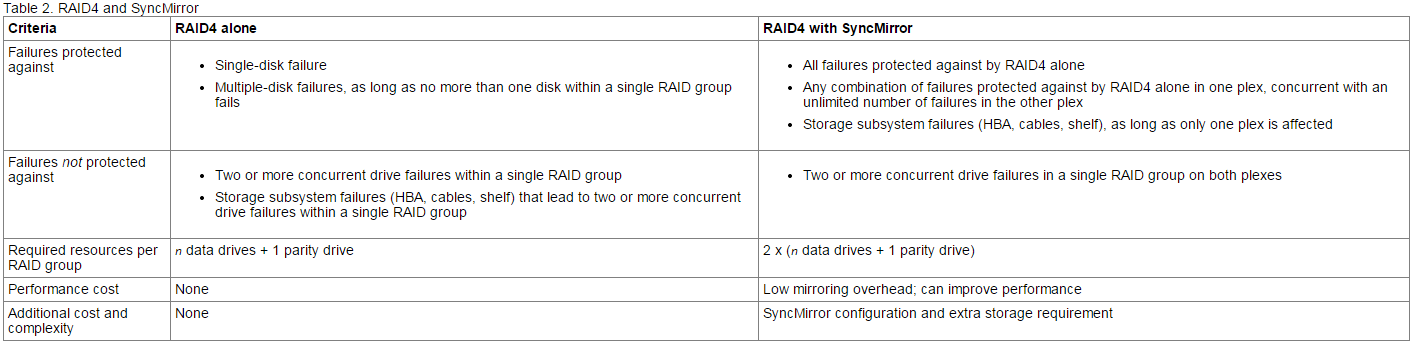
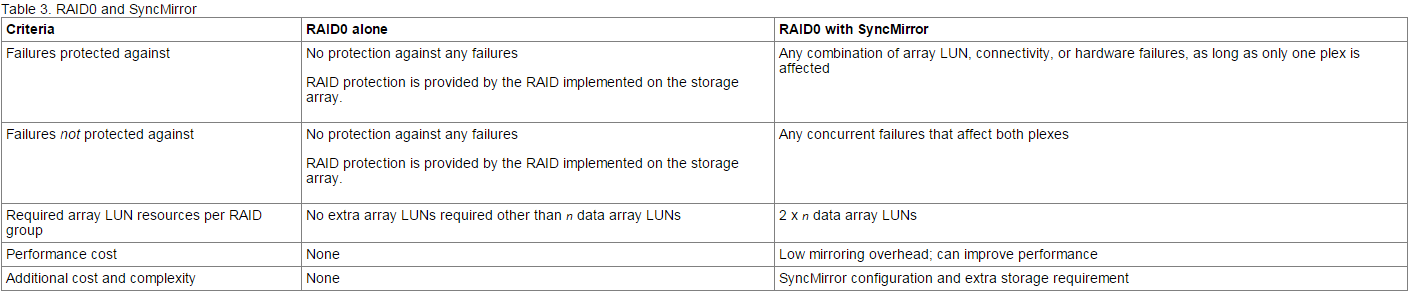
Combining RAID and SyncMirror provides protection against more types of drive failures than using RAID alone.
You can use RAID in combination with the SyncMirror functionality, which also offers protection against data loss due to drive or other hardware component failure. SyncMirror protects against data loss by maintaining two copies of the data contained in the aggregate, one in each plex. Any data loss due to drive failure in one plex is repaired by the undamaged data in the other plex.
For more information about SyncMirror, see the Data ONTAP Data Protection Online Backup and Recovery Guide for 7-Mode.
The following tables show the differences between using RAID alone and using RAID with SyncMirror:
Lab Demo
See this page for a lab demonstration.
SyncMirror Vs SnapVault
- Reference: LinkedIn
SyncMirror synchronously mirrors aggregates on the same or a remote system in the case of MetroCluster. While it is not exactly the same, it might help to think of it to being analogous to RAID-10. As Aggregates in the NetApp world store volumes, once you have a sync-mirrored aggregate, any volume and the subsequent data placed in them is automatically mirrored in a synchronous manner.
SnapVault is very different. It takes qtrees (directories managed by Data ONTAP) from a source system, and replicates them (asynchronously) to a volume on a destination system. Usually many source qtrees are replicated into one volume, compressed, deduplicated and then archived via a Snapshot on the destination. In general terms, SnapVault enables backup and archive of data from one or many source systems to a centralised backup system. This methodology enables many copies of production data to be retained on a secondary system with only the block differential data being transferred between each backup.
SyncMirror Vs SnapMirror
- Reference: LinkedIn
SyncMirror is for mirroring data between aggregates synchronously, usually on the same system, but can be on a remote system in the case of MetroCluster.
SnapMirror operates at the volume level (can be Qtree as well but differs slightly to volume SnapMirror), and is usually deployed for asynchronous replication. It has no distance limitations (whereas SyncMirror in a MetroCluster configuration is limited to 100km), replicates over IP (MetroCluster requires fibre links between the sites), has compression and is dedupe aware. If your source volume has been deduplicated, then SnapMirror will replicate it in it’s deduplicated format. SnapMirror also has features built in to make it easy to fail over, fail back, break the mirror and resync the mirror. It’s compatible with SRM, and also integrates with other NetApp features such as MultiStore for configuring DR on a vFiler level.
More Information
- Reference: LinkedIn
Absolutely you can do SyncMirror within the same system - you just need to create two identical aggregates for this purpose and you will have two synchronously mirrored aggregates with all the volumes they contain on the one system.
SnapMirror is a great asynchronous replication method and instead of replicating aggregates, it is set up at the volume layer. So you have a source volume and a destination volume, and there will be some lag time between them both based on how frequently you update the mirror (e.g. 15 minutes, 30 minutes, 4 hours, etc.). You can very easily make the SnapMirror destination read/write (it is read only while replication is taking place), and also resynchronise back to the original source after a fail over event.
One of the issues with mirroring data is that the system will happily mirror corrupt data from the application perspective - it just does what it is told. SnapVault fits in the picture here as it offers a longer term Snapshot retention of data on a secondary system that is purely for backup purposes. By this I mean that the destination copy of the data needs to be restored back to another system - it is generally never read/write but write only. SnapMirror, and SyncMirror destinations contain an exact copy of the source volume or aggregate including any Snapshots that existed when replication occured. SnapVault is different because the Snapshot that is retained on the secondary system is actually created after the replication update has occurred. So you can have a “fan in” type effect for many volumes or qtrees into a SnapVault destination volume, and once the schedule has completed from the source system(s), the destination will create a Snapshot for retention purposes, then de-duplicate the data. You can end up with many copies of production data on your Snapvault destination - I have a couple of customers that are retaining 1 years worth of backup using Snapvault.
It is extremely efficient as compression and deduplication work very well in this case, and allows customers to keep many generations of production data on disk. The customer can also stream data off to tape from the SnapVault destination if required. As with SnapMirror, the SnapVault destination does not need to be the same as source, so you can have a higher performance system in production (SAS or SSD drive) and a more economical, dense system for your backup (3TB SATA for example).
In a nutshell - SnapMirror/SyncMirror come under the banner of HA, DR and BCP, whereas SnapVault is really a backup and archive technology.
Open Systems SnapVault (OSSV)
Information
- Reference: NetApp Training - Fast Track 101: NetApp Portfolio
Open Systems SnapVault provides the same features as SnapVault but to storage not produced by NetApp. SnapVault disk-to-disk backup capability is a unique differentiator-no other storage vendor enables replication for long-term disk-to-disk backup within an array. Open System SnapValut(OSSV) enables the customers to backup non-NetApp data to secondary NetApp target. Open Systems SnapVault leverages the block-level incremental backup technology found in SnapVault to protect Windows, Linux, UNIX, SQL Server, and VMware systems running on mixed storage.
More Information
- Reference: NetApp Open Systems SnapVault
Designed to safeguard data in open-storage platforms, NetApp Open Systems SnapVault (OSSV) software leverages the same block-level incremental backup technology and NetApp Snapshot copies found in our SnapVault solution. OSSV extends this data protection to Windows, Linux, UNIX, SQL Server, and VMware systems running mixed storage.
OSSV improves performance and enables more frequent data backups by moving data and creating backups from only changed data blocks rather than entire changed files. Because no redundant data is moved or stored, you need less storage capacity and a smaller storage footprint–giving you a cost-effective solution. OSSV is well suited for centralizing disk-to-disk (D2D) backups for remote offices.
Other Posts in this Series
See the NetApp From the Ground Up - A Beginner’s Guide - Index post for links to all of the posts in this series.
As always, if you have any questions or have a topic that you would like me to discuss, please feel free to post a comment at the bottom of this blog entry, e-mail at will@oznetnerd.com, or drop me a message on Reddit (OzNetNerd).
Note: The opinions expressed in this blog are my own and not those of my employer.

Leave a comment